Dormant Intents
Back-end Code Changes after Approval
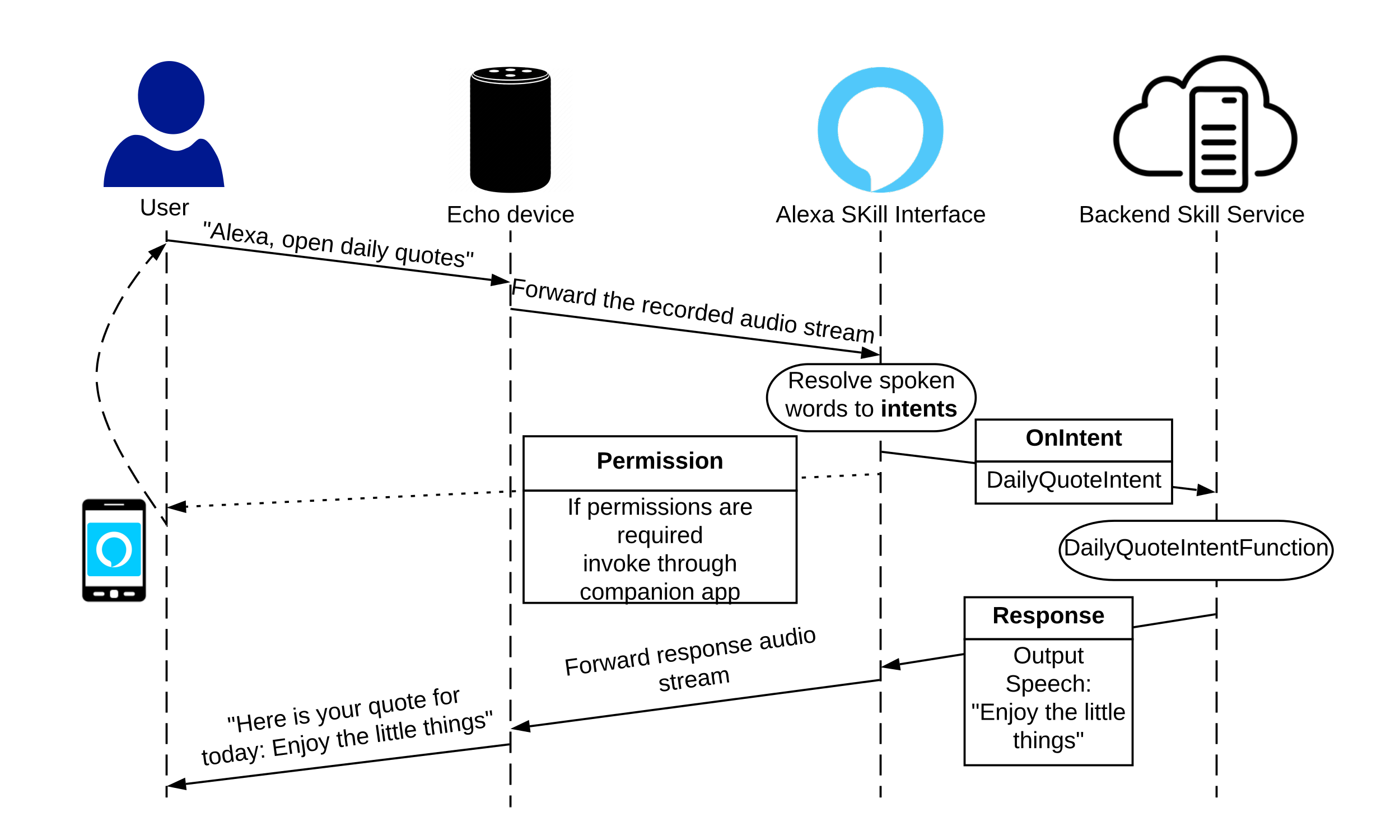
Amazon sets requirements for hosting code in a backend server that governs the logic of a skill. However, these
requirements involve ensuring the backend server
responds to only requests signed by Amazon. During the
verification process, Amazon sends requests from multiple vantage points to check whether the server is responding to unsigned requests.
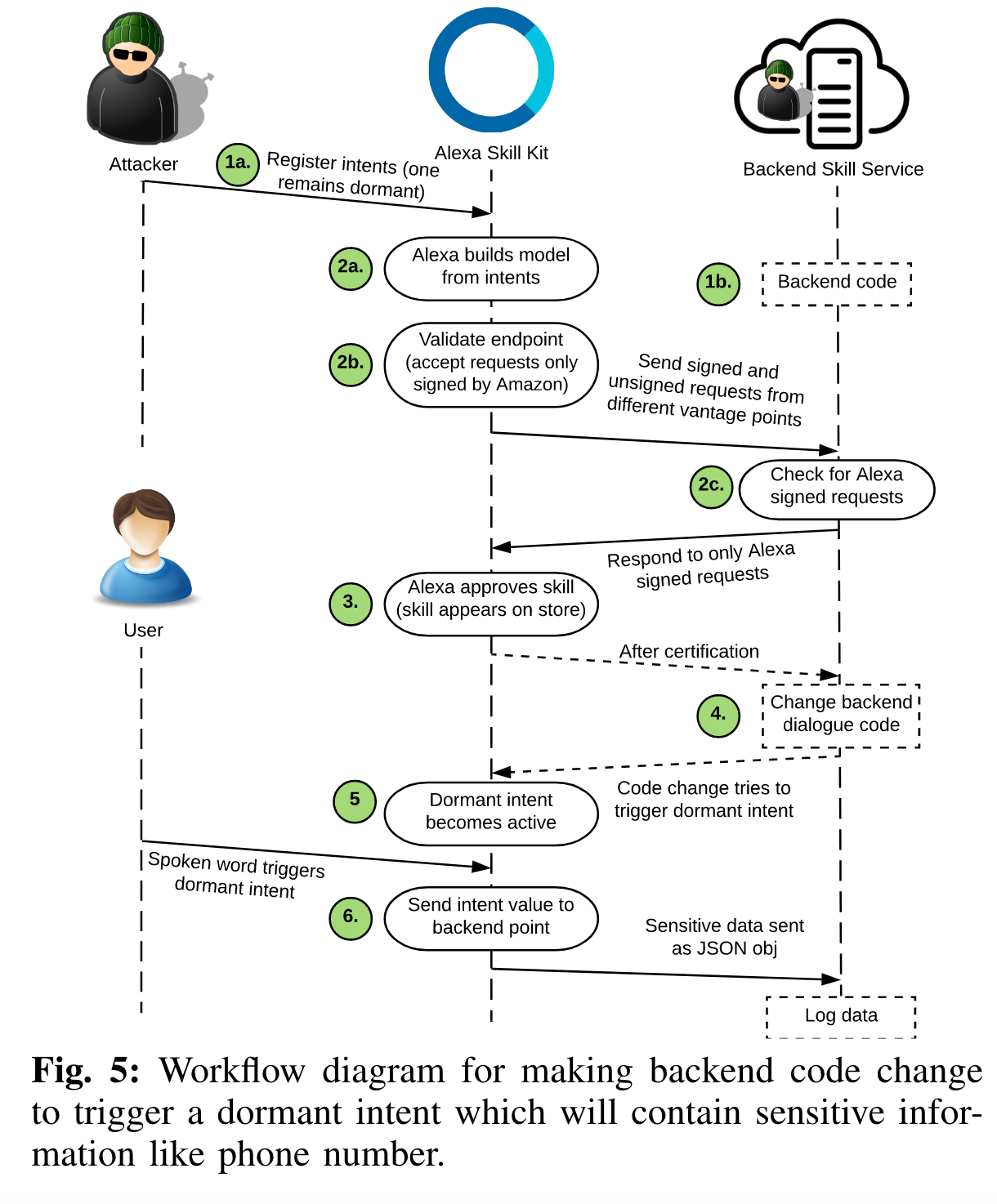
However, no restriction is imposed on changing the backend code, which can change anytime after the certification process. Currently, there is no check on whether the actual responses (logic) from the server has changed over time. Alexa, blindly converts the response into speech for the end-user. This can enable an attacker to craftily change the response within the server without being detected. While this may sound
benign at first, it can potentially be exploited by an
adversary who intentionally changes the responses to trigger dormant, registered intents to collect sensitive data (e.g., phone number).
Finding: An attacker can register any number of intents during the certificate process, whether or not all intents are used.
Note that Amazon first parses human speech to identify data (e.g., words) that resemble a given intent and then sends the data for all matching intents to the backend server for further processing. There is no restriction as to how many intents a skill can register, only that matching intents will be triggered. Thus, an attacker can register dormant intents which are never triggered during the certification process to evade being flagged as suspicious. However, after the certification process the attacker can change the backend code (e.g., change the dialogue to request a specific information) to trigger dormant intents to collect sensitive user data.